Dependency Inversion Principle
Categories: Android development job DIP SOLID
Tags: job description DIP SOLID

This article has two goals. Emphasizing the "Dependency Inversion Principle", DIP, and making it more exciting by explaining who I am and what kind of job I'm looking for!
Above wallpaper reference1
The reason that I mixed these two goals is that you probably already know everything about DIP, but it's unappreciated in my opinion, so instead of going from \(A\) to \(B\), \(A \rightarrow B\), I'll try the following.
\[ A \rightarrow (some\ facts) + (my\ story) + (some\ emotions) \rightarrow B \]
To make the facts more memorable, along with me and my story. In the end, this is how our brain works to memorize stuff, by anchoring them to stories, so let's do it. Eventually, you folks inevitably will call me DIP at some point in the future, because I keep repeating in my articles, posts, documents, and toots that by using DIP you can decrease your build time, you can do this, you can do that, etc. And that's a truth, due to the fact that I am very successful to getting deep into understanding stuff. As a matter of facts, back in schools and universities, I didn't memorize a lot of formulas. Instead of memorizing, I always dived deep into the problems to reach to the first principles, then derived the needed formulas. "DIP", "deep", is it clear?
Obviously, the story will get old in the future, but I try to write it in a way that keeps it useful for understanding DIP.
Also in the middle of the train of thoughts I have to mention that as long as this article can convey the meaning, I am satisfied with its level of grammar and spelling correctness. In the era of LLMs, like ChatGPT, I want to insist that this article is generated by my brain, even if there are some grammar or spelling mistakes here and there. Although, some old methods like searching the words in some search engines are used here!
Here, I consider the mixing of these two goals as story-telling, and training, skills. Also, this story supposed to have different levels for different readers to feel connected, have a non-linear story, and of course be a memorable one. If you are a fan of these properties, you'll enjoy it, otherwise, please bear with me, or assume you are watching Tenet! Thanks!

What is DIP?
Don't expect me to answer it in the traditional way! I'll explore the whole space with you to give you its sense. Also, you may not agree with me, which is great if you let me know why. Contact me via email, or message, in any platform that I mentioned in the main page of this website.
Based on its name, "Dependency Inversion Principle", and its acronym, DIP, it looks like it must be a very hard thing to grasp, but it's not. Indeed, DIP is secretly everywhere, because it's a simple concept, but nobody talks about it! Here, we want to talk about it. Before anything else, you need to know about what's an abstraction. Recently, I watched this great video that explained it much better than I ever could, so let's watch it first.
From the video, I want to repeat Henri Poincaré's2 saying here.
Mathematics is the art of giving the same name to different things.
So an abstraction is basically naming in a way that you could replace the underlying objects frictionlessly. The art is to find a pattern that its objects are replaceable. In other words, the objects must have something in common to attach the naming to it, and also, they should be independent of each others, so we could substitute them.
But "what's the DIP?"! The DIP is that naming when you are abstracting! It's simple now, right!
I would say, I don't get it! Where's the "dependency", "inversion" in "naming" and "abstracting"?
Let's use an abstraction, the image below, to explain this abstraction, which is clarifying how we use an abstraction!
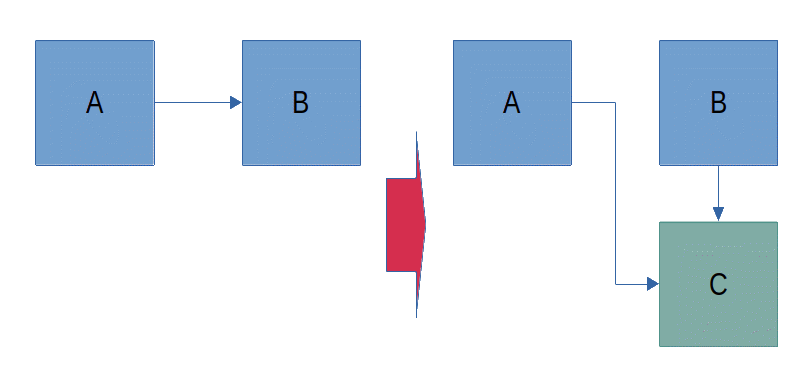
Here, we have implementation \(A\), and implementation \(B\), then we define the interface \(C\) to abstract \(B\), to define the input and output, IO, of \(B\), so \(A\) knows what should be expected from \(B\). Notice, the dependency arrow that ended to \(B\) on the left side of the image, but got reversed and starts from \(B\) afterward, which explains the "Inversion" in DIP. With this method, we will isolate \(B\). Isolation will help frictionless moves for \(B\), because it only needs to satisfy the IO that's defined in \(C\), no more, no less.
Before moving further, let's use a Venn diagram to show what's going on.
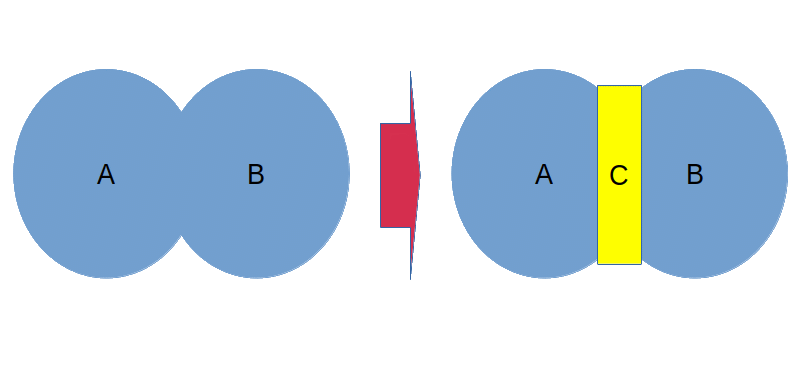
So \(B\) is hiding behind the \(C\). In an abstract world of programming and math, everything is an abstraction, so \(C\) surrounds \(B\) entirely. Therefore, it is more like this
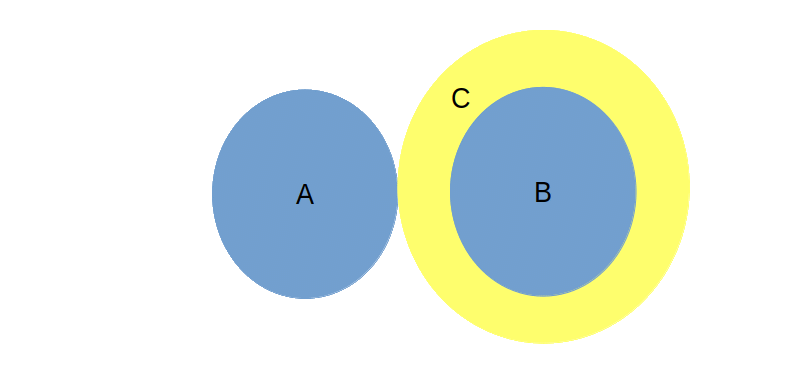
So \(C\) is hiding \(B\) entirely. Be aware that, this is not happening only in abstraction worlds, because we borrowed it from the real world. In the real world, every \(3D\) object is surrounded by their \(2D\) surface on its boundary, so the inside of objects are always hidden from any observer. This is the ultimate privacy policy of the nature, if you accept only solids as objects and forget about all kind of waves, light or sound, that can penetrate to every object! But black solid objects are enough to learn DIP from, right? So we can learn from the nature and use interfaces in DIP as the surface that wraps the implementations.
But what's the point of this struggle? The point is that when you want to prove something, the same as what's happening in the above video, you need to
- Repeat something
- Reuse an implementation
- Having multiple implementations/proofs, so you want to substitute them seamlessly.
- Hide the details of implementation/proof
- Isolate the implementation
So you can use the name of the abstraction to reference the implementation, and inject the needed implementation, as the dependency, whenever it's needed. Notice, the above list is sorted from easy to understand and apply, to the hard one.
Notice, that we used implementation and proof interchangeably above. If you want to get deeper the reason is Curry–Howard correspondence3.
In the Curry–Howard correspondence3 context, anything that we consider as a logical proof is actually equivalent to constructing something out of types or compositions. In this context, it turns out that the process of constructing is exactly the imperative steps we're doing in programming a code, therefore, any implementation in a programming language, that can implement Turing machines4, is actually a proof in the mathematical sense.
Now I just need to explain what's the Turin machine. But don't worry about the details! All imperative programming languages, that are common, can implement a Turing machine, such as Python, JS, Java, Kotlin, Rust, C, C++, etc. Thus, whatever you are implementing in those languages is proving something, by just constructing the details line by line.
The question I would ask is that why we need to "reuse", "repeat", "hide", "isolate", etc. in the first place. The answer is very essential to be self-aware of what we're doing here. We need them to simply solve our problems, right? The DIP allows us to decouple implementations. Hope we agree that being independent in a structure means they are decoupled from each others. In fact the last reason, which is the isolation, is the most important reason to use DIP. Isolation will make implementations/proofs/objects independent of each others, and finding such a pattern is the art Poincaré is referring to.
In the first glance, this decoupling and isolation is very useful for our small brain that only can deal with a very small number of parameters, so maybe that's why we're addicted to DIP and use it everywhere. But if you get deeper, you can see this approach in the places of nature that doesn't need any memory at all!
For instance, our body has organs, which have defined IO, so they can decouple their work from each others. Therefore, DIP is extensively used in our body. My favorite organism that's using DIP is slime mold5, because you can easily observe that it's just single cells that are totally independent of each others, but they can scale up a structure to be visible to the naked eyes. Of course, the definition of their IO is hard coded in their DNA, but they work in harmony to scale up their structure much bigger than individual cells. Thus, DIP is the secret to scalability in the nature, and we can learn from them.
We can jump from organisms to organizations, and it's a known fact. I strongly advise taking a look at "How organizations are like Slime Molds"6. But unfortunately, it's not known that we can do this because of DIP, and its required independent cells.
DIP is another face of the abstraction coin, therefore, DIP is used by the first human being, who could think of some abstractions. It's old. It's everywhere. However, it rediscovered multiple times in the history of math. For instance, Euclid reinvent it when he constructed geometry based on his 5 axioms, because he could isolate the theorems from those axioms. By the way, notice axioms are abstractions without implementation, like when you write a code and have a dependency to an API from the OS, but you have no clue what the implementation is.
Move forward for centuries, Descartes and Newton rediscovered it in the vector space, which is basically a set of structures with independent components. We can decouple the components by using the defined interface of inner product between vectors. This revolutionized engineering, because instead of solving problems for 3 dimensions altogether, we could solve the problems for each dimension separately. So the big bridges and buildings started to appear everywhere. Notice, we're talking about scaling up. And again, this proved to us that decoupling is the key to problem-solving.
Rediscovering DIP didn't finish there, in the Quantum Mechanics, we found all states can be decoupled and we can build a Hilbert space7 with them. It doesn't stop there! Also all particles are independent, so we have a space for each of them, where we can build a bigger space for the state of all particles together. By the way, this space leads us to the Quantum Entanglement8, which I don't need to emphasize anything about it here.
And finally, programmers rediscovered it in the name of DIP. End of history story!
To summarize, we need hiding the details, and also, having replaceable and independent components, to break down any hard problem and solve it piece by piece. So if anyone asked you what's DIP, it's
- Hiding the details by defining only the inputs and outputs.
- The IO definition must stay consistent over time.
- Making independent implementation and interfaces out of those details.
The rest of its properties can be deduced from these three.
Even all the SOLID principle could be deduced from these.
The Single responsibility principle, which stands for S in SOLID, is having independent implementations, and also independent interfaces.
The Open-close principle is exactly the consistency of the defined IO over time.
The Liskov substitution principle is the independent, so replaceable, components.
The Interface segregation principle is the requirement that the interfaces themselves should be independent too.
Here, it's a good time to remind you that interface in Java, and Kotlin, is the abstraction,
where abstract class is not the abstract we're talking about here, because it contains implementation.
In fact, if you only want to make your code unmaintainable in the long run, use abstract class in your code.
The reason is that abstract class and open class are the coupled implementations we wanted to avoid in the first place.
However, the solution is composition, instead of using abstract class.
What's its practical usage?
Among the practical usages for DIP, I think the followings are the most important ones.
Flattening the dependency graph
The dependency graph is a directed graph that shows the dependency among the components of the project. In Java and Kotlin ecosystem modules have independent build cycle, but you can do it on any other programming languages, just find out how to manage independent builds.
But why it's good to flat it out? The reason for that is the build time. Whenever a module got changed in the development cycle, only its build and the modules that depend on it will be invalidated, which mean they need to be rebuilt. Of course, rebuilt is time-consuming, so we want to minimize their number. By flattening the dependency graph, only the root module is depending on the modules that contain implementations. In other words, no implementation module is depending on another one. They are only connected via their interfaces. So in case of the changes in the implementations, the build of the changed module along with the build of the root module will get invalidated, thus, only two modules need to be rebuilt. This is a must if you want to scale up.
To achieve it you need to have two modules.
One of them should include the implementation. Usually we call them impl module.
The other one should include the interfaces and data/value classes in the way to define the IO of that implementation.
Usually we call them io, or public, or api, module.
Then impl modules only depends on io modules, except the root module that can depend on every module in the project.
This will guarantee a flat dependency graph, which is needed for scalability.
I love the fact that with old and slow hardware, design of the programming languages like C and C++ forced the developers to depend on the header files, which are the abstraction of the implementations, instead of letting implementations depend on each others, so they could scale much better and built amazing things in those old days. But by improving the hardware, we got careless and allow the implementations to depend on each others to create such slow environment respectively.
Using DIP in feature flags
Whenever you need to deliver a new feature, you can create a branch in your source controller, like git, but this approach has a very big disadvantage for big features, because it's impossible to keep all the feature branches up to date, and it will cause big conflicts. The solution is to keep all the features in the main/default branch and use virtual branches, aka feature flags. DIP is useful to make the switches clear. The big feature should be hidden behind one or more interfaces, then we need one empty/null implementation for those interfaces, and one real implementation. Whenever the flag is OFF, we inject the empty/null implementation, and whenever the flag is ON we inject the real implementation. In this way, we can use all the advantages of DIP too, like isolation and hiding the details.
The flags can be turned ON or OFF on the compile time, or runtime. Specifically, on the runtime we have two more options to switch them on a UI dialog or remotely.
Using compile time feature flags
Sometime you have security concerns to not ship a not-completed, or not-reviewed, feature.
If you have a flatten dependency graph in place, for the feature you want to remove, you need to have another module.
The empty/null implementation module.
Usually we call them null module.
It would reside beside the impl and io modules, and has empty implementation for the io module.
Then you need some mechanism to replace impl with null module on the compile time.
So whenever the build includes impl it cannot include the null and vice versa.
And in the end, you need a compile time code generator to wire up what's included, which means, to inject the included implementation.
For this step, I was using Anvil, but having an independent code generator is not too hard to implement.
By the way, I wrote about some of these before in my previous article "Are feature flags, build variants, and sample apps related concepts?"9.
Using DIP in A/B testing
There are multiple ways to do this. If you don't know what's A/B testing, it's not a hard concept! Imagine turning ON and OFF two features to statistically compare users' responses to the changes. We're going to refer to those features, the cases of A/B test.
- You can have a single interface that abstracts two implementations.
- You can have two interfaces for each of cases, but for each case, you need to have an empty implementation to switch to when that case is off. This one is so similar to a remote feature flag.
Updating a feature independent of the rest of the client app
The only principle in Agile that I respect is looking at the delivery of the code as experiments, even though, they don't mention that it should be treated like a scientific experiment.
So let's make it a concrete statement. In software, we need to deliver and measure the code with the scientific method standards continuously. But the biggest problem is that only dynamically typed programming languages allow you to download the latest update, and replace the code continuously, of course without disturbing the user. But for scaling, a statically typed programming languages are needed. This looks like a trade-off, until you notice that DIP allows you to version the interfaces, then dynamically deliver the implementation and cast the implementation to the already available interfaces. This means you can have all the necessary building blocks for the scalability of the project and continuously experimenting.
How to do it wrongly?
To do it right, you need to make sure you are hiding the details within a clear IO definitions, and those details should be independent. So if you don't do it in this way, you can end up with a wrong interface and data classes. I'm sure you have seen a lot of examples in the codes you read before, but here I have two examples that will let your mind think out of the box, of programming.
For starter, this article is an example of doing it wrongly, because it violates the single responsibility principle. However, it's how our brain works to remember things, so it was a trade-off to choose when I started to write it.
Another great area of examples is how lawyers, and rule makers, use it often! It's not so strange that they use DIP, because they need to abstract the property of the society and for that they need DIP. The problem is that they didn't discover the rest of SOLID principles yet, or at lease, their components are not independent or carry only one responsibility. Before going any further, I have to mention that I have no expertise in those areas, and I am just observing it from the outside. Maybe they wanted me to remember it forever in the same way as what I did to you in this article. Or maybe they are doing great. I'm sure you have better examples how they hide the internally connected implementations all the time. My point is not let's fix them. My point is to provide a vast area of examples of not-to-do, which is great for learning purposes. Anyway, here it's the story.
In my agreement with my current company they mentioned the "Ontario Employment Standard Act", ESA, therefore, by this interface they injected a lot of terms to the agreement, which looks okay until here, because I knew it and I read most of them. However, my work permit was bound to the employer, which is called LMIA work permit, and there's no mention of it in the agreement. But let's assume I agreed to LMIA terms, because I applied for that at some point in a different process and with different forms. The problem is that "LMIA work permit" is internally connected to the ESA, because it has some terms regarding the limitation on increasing the salary, which can be discussed by its own on the violation of human rights. As the result, my carrier is frozen for more than two years now because of these terms, even though, my managers and company clearly saw my potential to add value to the company by promoting my title and salary, it didn't happen due to this restriction.
Hope, even if you didn't realize the consequences of wrong DIP in our everyday software, now you saw the scale of doing it wrong. The bright side is that I experimented that what I'm saying is what I'm doing consistently, because even after failure to get promoted, my body could deliver enough dopamine for my work that I managed to successfully deliver great works for my company. The works that you expect from someone with the title of Principal Software Engineer, or Software Architect. In fact, my friends with the Software Architect title continuously asking for joining me to meetings and advocate.
Why do I think DIP is unappreciated?
Let's do more story! I am Hadi 👋 I'm from Iran. Stress factor is my biggest enemy. I studied Theoretical Physics, and I was a lecturer for a while. Then started working on Android development. On 2019, my family, and I, moved out of Iran to Barcelona/Spain, so I could work on my favorite project at the time, Letgo. After their layoff, they supported me to work at iFood, which had the same parent company, OLX. However, on the event of the layoff, I've also applied to MobileLIVE, which its process took almost 9 months, until we could move to Toronto/Canada. After a while and noticing that there's no promotion, as I mentioned the reason above, in the hope that big companies have the power to sort it out, I applied to some of them, Google, Amazon, Uber, Block, etc. In the end, I could only make it to the second round of interviews for all of them, but I learned one or two things that I want to share here.
No DIP question in interviews
In all the interviews there was not a single question related to DIP. Which shows why these big companies struggle too much to scale up, because they hired people who are not verified that has the ability to solve the big problems. Be aware, that I am not claiming that they don't have this ability. In fact, I found the interviewers so knowledgeable, calm, kind, and respectful. My point is that solving software problems without DIP is like trying to solve problems in Newton Mechanics without knowing the vector space. Not just solving problems, try to build a big bridge, or building, without the vector space. Notice, the comparison here is one to one, which means vector space is the tool to make independent components, the same as DIP in programming.
You may think that maybe only in the so-called "Algorithm and data structure" interviews there's not DIP related question,
but in the "System design" interviews all the components are independent, and it's all about interfaces, right?
Wrong! First of all, using any kind of types, including interfaces, is a disadvantage in the "Algorithm and data structure" interviews.
Remember, types are defining the building blocks of your construction, so programming without types is like building a sand castle.
Imagine a world that the requirements for engineers who wanted to build a big castle are evaluated based on their ability to build a sand castle!
It doesn't make sense!
However, I tested it and interviewer was looking at them like boilerplate code!
For instance, if you know what's the ViewHolder in Android, in one interview,
I tried to separate the data, which is the input of the ViewHolder in a data type,
as I would do in the real life, and then only manipulate the order of the data in the list, to handle the order of ViewHolders.
You've guessed what's happened.
Secondly in the "System design" interviews, they care about the performance, latency, and even fault-tolerant system, not having independent components, or what's the definition of IO. Even if they ask such questions, it'll not prove anything, in my humble opinion.
One interviewer accused me that I didn't take the simplest solution, which I still couldn't digest! Because it looks like I can see the patterns well. As you can see in this article, I can see a pattern in math, physics, biology, management, software, and I can construct giant structure with them, where, in my humble opinion, such a factorization is the definition of the simplification. Notice, I'm not saying they observed wrongly, because I was stressful and lost my sleep over it, so they probably observed correctly, but what they observed is not me generally!
Fortunately, some of these interviews give you feedback, where I learned that whenever the interviewer is asking about the exact same thing that you already explained, don't repeat your solution. You can think outside the box. Give them another solution. It's only an interface between the interviewer and the interviewee, so follow the rules!
What job I'm looking for?
The news is that I received my Open Work Permit this month, so it's the time to switch my job. In my opinion, I have all the needed skills to handle an entire project, including having the knowledge, managing, training, and communicating. The clues to my abilities that make me confident are how other developers interact with me. In the team of more than 50 Android engineers, they directly reach out to me, before reaching out to the managers, to solve their problems. Even for problems that are obviously out of my hand. By the way, it's happening even for seniors who knew me for more than two years now. Which shows I've solved many hard problems, and I've helped them a lot before, thus, it's a pattern in their mind that I can solve this one too. I have to mention that we have skilled and reachable managers to avoid any confusion here.
I don't want to restrict this job description by the title, because at this point I am confident that I can handle a title like CTO for a fairly big project, but you may argue that I don't have the experiment. In such a situation, I would argue that the only experiments that matter are the repeatable, and measurable, ones, by following the scientific method, which means I have what is needed. And of course, there's a lot to learn, and I am humble and thirsty to learn more. The only problem that I can see is building the trust bridge, especially before I start, but I am looking forward to working it out.
Despite the fact that I have a lot of new ideas how to hire and manage a successful project, but I don't want to be a manager! I want to stay close to the code as my dopamine release is much higher when I interact with the code, The excitation of solving big problems is what derives me well. Therefore, I am looking for a job that adds value to the society by solving big enough problems.
The other point here is that I'm always looking to my work as an investment, which means in my mind I am a shareholder, so for the sake of consistency between my mind and the reality, and also, achieving true independency, I am looking for a job that treats me like a shareholder, and also, shares fair amount of stocks or options. By the way, I want this point for my team too, because I want to have them independent as well. Of course the details are negotiable.
Being independent and be able to organize other engineers in the independent manner, by only defining and measuring the input and output of the components, is what guarantees scalability and success, thus, if you are hiring for such an environment, I am your best choice.